|
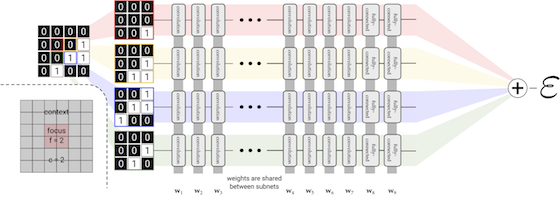
In this article, we demonstrate a new type of deep neural network which is designed for the purpose of dividing a problem into many parts so that it can be efficiently worked on in parallel. Traditional neural networks have been optimized for operating on data which is scale invarient. Our new extensive neural networks maintain the property of additivity across sub-domains. This is an important property in physical systems. Our new EDNN operate at the same accuracy of previously reported work, but can be distributed over many GPU in parallel, making them ideal for use on massively parallel computing architextures. Additionally, EDNN operate on arbitrary sized inputs, so they can train on small structures, but be used to predict the properties of giant ones.
For example implimentations, see our code section |