|
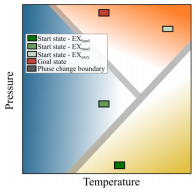
Reinforcement learning (RL) has been demonstrated to have great potential in many applications of scientific discovery and design. Recent work includes, for example, the design of new structures and compositions of molecules for therapeutic drugs. Much of the existing work related to the application of RL to scientific domains, however, assumes that the available state representation obeys the Markov property. For reasons associated with time, cost, sensor accuracy, and gaps in scientific knowledge, many scientific design and discovery problems do not satisfy the Markov property. Thus, something other than a Markov decision process (MDP) should be used to plan / find the optimal policy. In this paper, we present a physics-inspired semi-Markov RL environment, namely the phase change environment. In addition, we evaluate the performance of value-based RL algorithms for both MDPs and partially observable MDPs (POMDPs) on the proposed environment. Our results demonstrate deep recurrent Q-networks (DRQN) significantly outperform deep Q-networks (DQN), and that DRQNs benefit from training with hindsight experience replay. Implications for the use of semi-Markovian RL and POMDPs for scientific laboratories are also discussed.
|