|
Active Measure Reinforcement Learning for Observation Cost Minimization
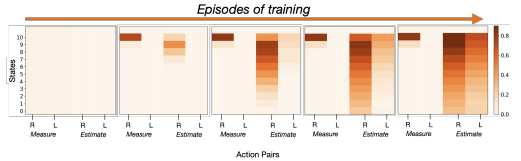
C. Bellinger, R. Coles, M. Crowley, I. Tamblyn Canadian Conference on AI, 37, 2021L10 (2021) In many real-world scientific and engineering applications, measuring the state of a system after each action is costly or time-consuming, yet standard reinforcement learning algorithms assume free access to state observations at every time step. In this work, we introduce Active Measure Reinforcement Learning (Amrl), a framework in which the RL agent can freely explore the relationship between actions and rewards but is charged each time it measures the next state. The Amrl-Q agent learns to balance the value of obtaining accurate state measurements against their cost, progressively transitioning from relying on costly direct measurements to leveraging a learned transition model of the environment. The approach is shown to outperform standard Q-learning, Dyna-Q, and POMCP planning baselines, demonstrating that intelligent observation strategies can significantly reduce measurement costs without sacrificing policy quality. |