|
Dynamic Observation Policies in Observation Cost-Sensitive Reinforcement Learning
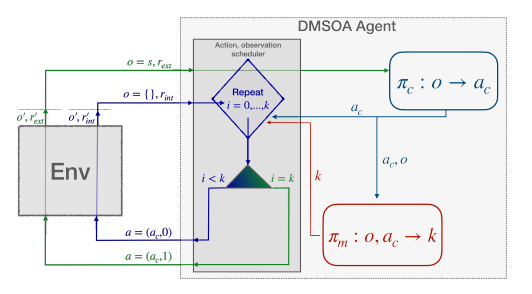
C. Bellinger, M. Crowley, I. Tamblyn Workshop on Advancing Neural Network Training: Computational Efficiency, Scalability, and Resource Optimization (2023) Standard reinforcement learning assumes that environmental state measurements are freely available at every time step, but in many real-world domains such as materials design, deep-sea exploration, and medicine, observations carry substantial costs. In this work, we introduce the Deep Dynamic Multi-Step Observationless Agent (DMSOA), which learns dynamic observation policies that strategically decide when to measure the environment versus acting based on prior knowledge. Rather than observing at every step, DMSOA enables agents to make decisions across multiple steps without fresh state information, explicitly balancing the tradeoff between measurement costs and decision quality. Evaluated on OpenAI Gym control tasks and Atari Pong, DMSOA learns better policies with fewer decision steps and measurements than existing alternatives from the literature, demonstrating that intelligent observation scheduling can significantly reduce sensing costs without sacrificing control performance. |